
阶跃星辰 NextStep-1.1:自回归流匹配与RL改进
目录
分享
在国产大模型年底冲刺的热潮中——DeepSeek 的 OCR 与数学模型走红、Kimi 凭 K2 回归巩固口碑、智谱与 MiniMax 同步推动 IPO 并上新模型——“阶跃星辰”看似低调。但这种静默被 NextStep-1.1 打破:这款新图像模型针对 NextStep-1 曾出现的可视化失败进行修复,并通过扩展训练与基于流的 RL(后训练范式)显著提升图像质量与稳定性。

目录
- 为何 NextStep-1.1 重要
- 图像生成中的自回归流匹配
- 1.1 的关键变化:RL 与数值稳定性
- 发布状态与阶跃近期生态动作
- 中国大模型战场:Coding、Agent、多模态、开源与IPO
- 2026 展望:三大不可回避的问题
- 常见问题
- 结语
为何 NextStep-1.1 重要
NextStep-1.1 直击痛点:在高维连续潜空间下,NextStep-1 曾出现块状/网格伪影等可视化失败。1.1 通过 RL 增强与稳定性优化,证明自回归流匹配在不引入重型扩散堆栈的前提下,仍能逼近扩散式质量。这对希望在同一 Transformer 中统一文本与视觉的多模态系统,意味着吞吐、简化与落地的现实优势。
年底密集更新的竞合背景
- Kimi 借 K2 Thinking 与多云接入重拾势能;
- DeepSeek 依靠 OCR 与数学模型获得广泛关注;
- 智谱与 MiniMax 冲刺 IPO,同时发布 GLM-4.7 与 M2.1;
- 阶跃用 NextStep-1.1 展示其在通用模型与多模态 RL 上的持续投入。
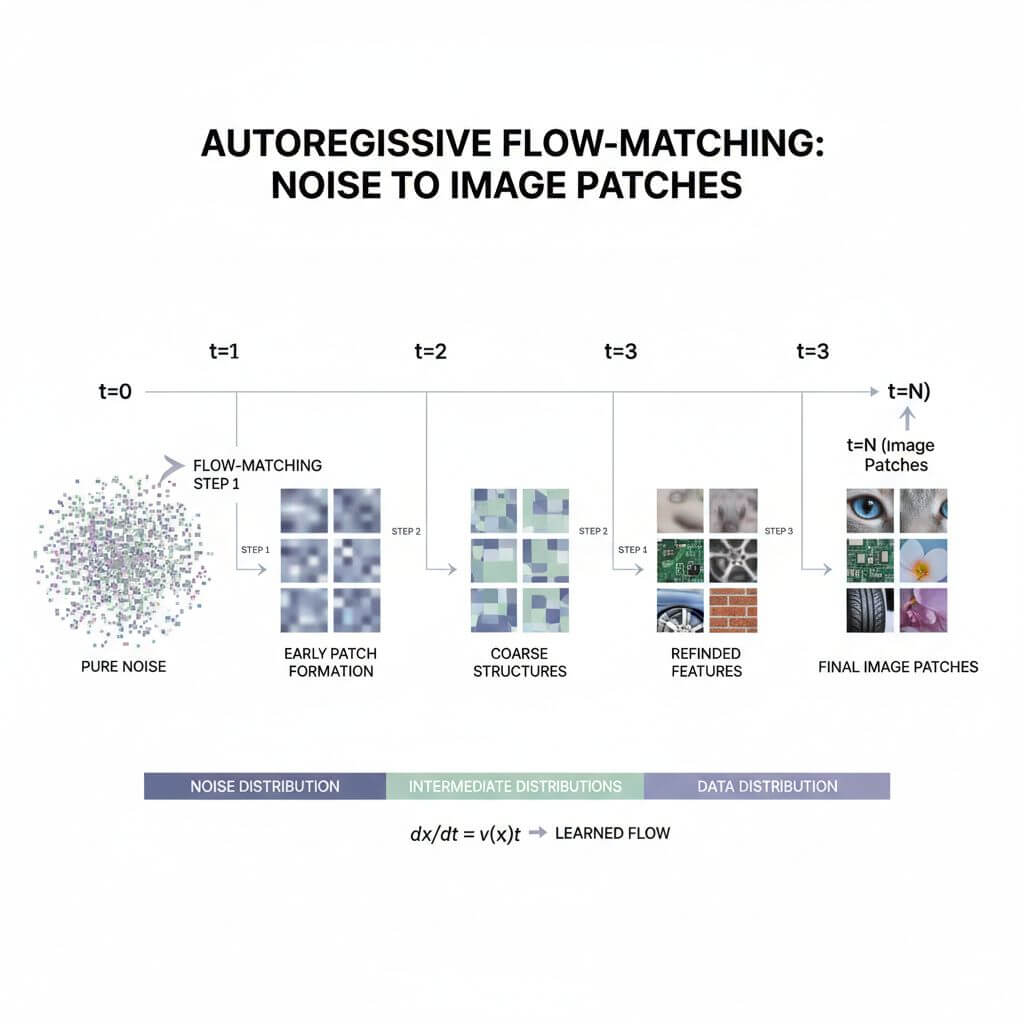
图像生成中的自回归流匹配
NextStep-1 使用统一的因果 Transformer 同时建模离散文本 Token 与连续图像 Token,以轻量的流匹配头替代“AR+重扩散”的常见混合架构。
架构概览
- 14B 参数因果 Transformer 主干;
- 标准语言建模头处理离散文本;
- 轻量流匹配头处理连续图像;
- 图像 tokenizer 产生 patch 级连续 Token。
训练机制
基于隐藏态,流匹配头预测从噪声到下一个目标图像 patch 的连续流轨迹,在同一 AR 堆栈内端到端学习。
推理机制
模型迭代地引导噪声走向下一个图像 patch,逐步拼合整幅图像,保持文本条件与图像生成的统一自回归循环。
1.1 的关键变化:RL 与数值稳定性
NextStep-1.1 引入扩展训练与基于流的 RL 后训练范式,聚焦视觉保真度与稳定性。两项改进尤为突出:
RL 增强视觉保真度
- 大幅减少块状、网格等伪影;
- 纹理更锐利,输出更清晰、专业。
数值稳定性修复
- 解决在高维连续潜空间下,自回归流匹配与 RL 结合带来的固有不稳定性;
- 通过稳定化避免 patch 不一致与接缝伪影。
在不回退到重型扩散堆栈的前提下,这些改进推动自回归流匹配质量进一步逼近主流扩散。
发布状态与阶跃近期生态动作
NextStep-1.1 已在 GitHub 与 Hugging Face 率先开源,技术报告尚未发布。自 11 月以来,阶跃的节奏并不“静悄悄”:
- GELab-Zero:主打安卓端本地部署与低门槛移动端智能体开发;
- PaCoRe(8B 推理):在数学能力上宣称超越主流基线;
- Step-GUI:整合 MCP 协议与云端模型,并开放端侧模型 Step-GUI Edge,深化智能终端布局。
这些举措体现“核心模型研发 + 终端/智能体生态”双轨策略。

中国大模型战场:Coding、Agent、多模态、开源与IPO
竞争版图正在重构:
- 技术主战场:Coding、Agent、多模态成为核心;
- 策略:开源生态正逐步成为默认选择,以扩大触达与加速迭代;
- 资本:智谱与 MiniMax 的 IPO 进程意味着第一轮“百模大战”后,胜者寻求更大杠杆,进入更广阔的战场。
从最初的“六小龙”到如今仍坚持自研通用大模型的四家:智谱、MiniMax、Kimi 与阶跃星辰。他们接下来面对的,都是巨头与“小巨头”,算力、数据与分发叠加效应更显关键。
2026 展望:三大不可回避的问题
- 是否仍具备端到端自研与预训练通用基础模型的能力?
- 粮草是否充足,能够支撑持续训练与快速迭代?
- 能否构建商业模式飞轮,实现产品—付费—再投入的可持续?
这些问题将决定谁能进入“决赛圈”,而不仅是“半决赛”。
常见问题
流匹配与扩散式有何不同?
流匹配直接学习从噪声到数据 patch 的连续流,迭代步数可更少,并可在单一 Transformer 中统一;扩散通常依赖独立的去噪模块与更重的采样管线。
NextStep-1 为何易出现伪影?
在高维连续潜空间中,自回归流预测与 RL 结合可能出现数值不稳定,导致块状/网格伪影与 patch 接缝问题。
1.1 的 RL 具体改进了什么?
后训练阶段聚焦视觉保真度目标,提升纹理细节、减少伪影、稳定 patch 过渡。
1.1 是否已有完整技术报告?
目前已在 GitHub 与 Hugging Face 开源,正式技术报告暂未发布。
与扩散式领先模型相比如何?
尽管扩散仍在多项基准占优,NextStep-1.1 表明自回归流匹配在保持单栈简洁的同时,质量可进一步逼近主流。
结语
NextStep-1.1 在自回归流匹配方向上迈出关键一步:以 RL 增强保真度、修复数值稳定性,却不回退到重型扩散。这一更新与今年“Coding—Agent—多模态—开源—IPO”的合流趋势相呼应,也体现阶跃在“核心模型 + 生态落地”上的持续投入。接下来两年,答案要在算力、数据与商业飞轮中被验证:谁能把自研基础模型做深、做稳,并做成可持续的业务。
分享
Sketch To
专注 AI 工具、图像处理和创意工作流的技术写作者。


