
NextStep-1.1: RL-Enhanced Autoregressive Image Generation
On this page
Share
Amid the year-end sprint of China’s large models—DeepSeek’s OCR and math wins, Kimi’s K2 comeback, Zhipu and MiniMax pushing toward IPO—Step (Jieyue Xingchen) has kept a low profile. That quiet broke with NextStep-1.1, a new image model that addresses visualization failures seen in NextStep-1 and significantly boosts visual fidelity through extended training and a flow-based RL post-training paradigm.

Table of Contents
- Why NextStep-1.1 matters
- Autoregressive flow-matching in image generation
- What changed in 1.1: RL and numerical stability
- Release status and Step’s recent ecosystem moves
- China’s LLM race: coding, agents, multimodality, open source, IPO
- 2026 outlook: three unavoidable questions
- FAQ
- Conclusion
Why NextStep-1.1 matters
Step re-enters the spotlight by fixing a core weakness: the visual artifacts and grid/block failures that appeared in high-dimensional continuous latent spaces under NextStep-1. NextStep-1.1 demonstrates that autoregressive flow-matching can be competitive with diffusion, while staying lightweight and single-stack. For multimodal systems that need tight integration between text and vision inside one Transformer, this matters for throughput, simplicity, and deployment.
Context in a crowded year-end wave
- Kimi regained momentum with K2 Thinking and broader cloud integrations.
- DeepSeek surged on OCR and a top-tier math model.
- Zhipu and MiniMax filed toward IPO while releasing GLM-4.7 and MiniMax M2.1.
- Step’s update shows continued commitment to pretraining general-purpose models and pushing multimodal RL.
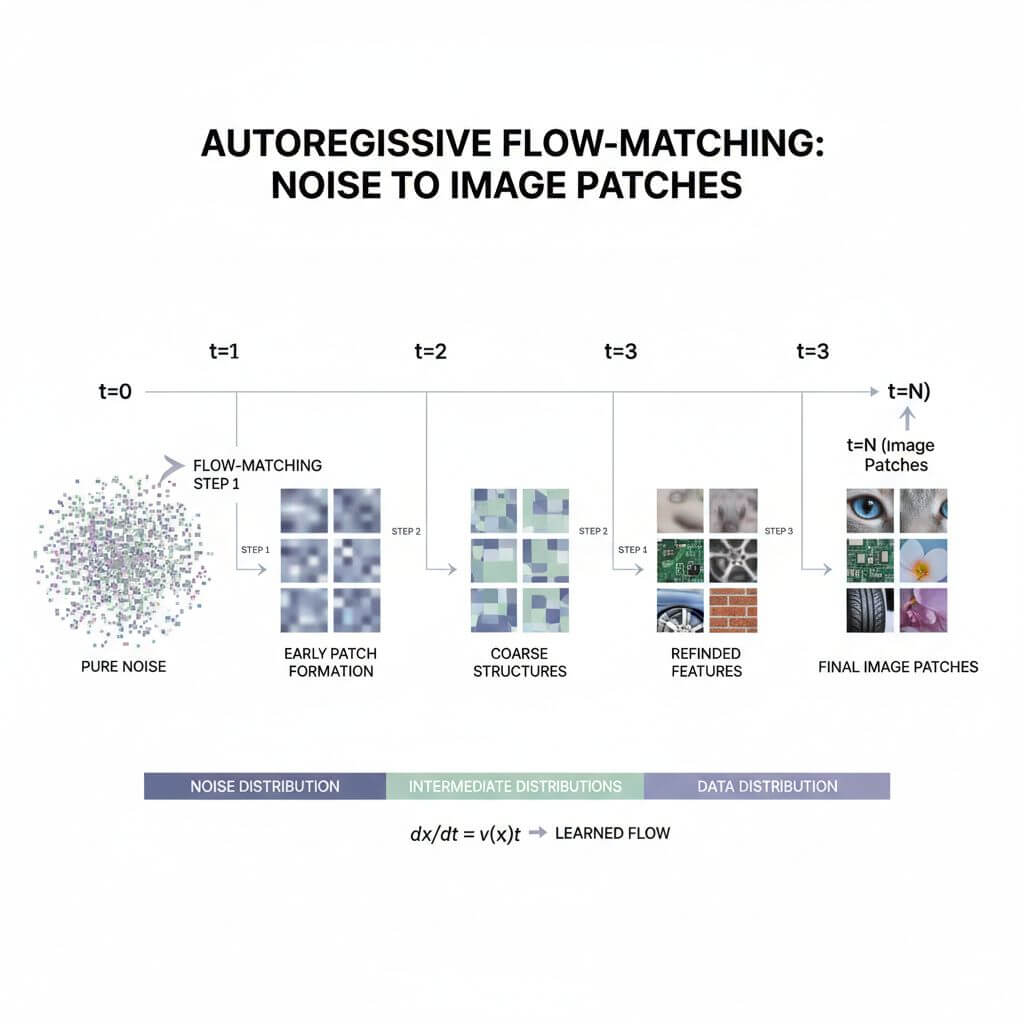
Autoregressive flow-matching in image generation
NextStep-1 adopted a unified Transformer to model discrete text tokens and continuous image tokens. It replaces the common “AR + heavy diffusion” hybrid with a single causal Transformer and a lightweight flow-matching head for images.
Architecture at a glance
- 14B-parameter causal Transformer backbone.
- Standard LM head for discrete text tokens.
- Lightweight flow-matching head for continuous image tokens.
- An image tokenizer that yields patch-level continuous tokens.
Training
The flow-matching head predicts a continuous flow from noise to the next target image patch based on hidden states. This yields a stepwise trajectory that can be learned end-to-end within the same AR stack.
Inference
The model iteratively guides noise toward the next image patch, progressively assembling a full image—keeping the AR loop unified for text-conditioning and image synthesis.
What changed in 1.1: RL and numerical stability
NextStep-1.1 introduces extended training and a flow-based RL post-training paradigm aimed at visual fidelity. Two improvements stand out:
RL-enhanced visual fidelity
- Significant reduction in visual artifacts (blocks, grids, haloing).
- Sharper textures and more professional clarity across varied prompts.
Numerical stability fixes
- Addresses instability inherent to RL over autoregressive flow-matching in high-dimensional continuous latent spaces.
- Stabilization prevents failure modes that previously produced inconsistent patches and artifacted seams.
Together, these changes move NextStep toward competitive quality without reintroducing a heavy diffusion stack.
Release status and Step’s recent ecosystem moves
NextStep-1.1 is open-sourced on GitHub and Hugging Face; a formal technical report is not yet published. Beyond NextStep-1.1, Step has maintained a steady release cadence since late November:
- GELab-Zero: local Android deployment and low-barrier mobile agent development.
- PaCoRe (8B inference): reported math performance surpassing leading baselines.
- Step-GUI: MCP protocol integration with cloud models and an open-sourced edge model (Step-GUI Edge) for intelligent terminals.
These moves show a dual-pronged strategy: core model R&D plus practical agent/terminal ecosystems.

China’s LLM race: coding, agents, multimodality, open source, IPO
The competitive map is shifting:
- Technical fronts: coding, agents, and multimodality now dominate.
- Strategy: open-source ecosystems are becoming the default posture for reach and iteration.
- Capital: Zhipu and MiniMax’s IPO trajectories indicate that after the first “hundred-model” phase, winners are leveraging capital to scale into larger arenas.
From the original “six dragons,” four remain committed to pretraining and general-purpose self-developed models: Zhipu, MiniMax, Kimi, and Step. Their next races will be against giants and “small giants,” where compute, data, and distribution compound.
2026 outlook: three unavoidable questions
- Can they still self-pretrain foundational general models, end-to-end?
- Is the war chest deep enough to sustain the training and iteration cycles?
- Can they build a business flywheel—product-market fit, monetization, and reinvestment—to sustain independent R&D?
These will define who reaches the finals, not just the semifinals.
FAQ
How does flow-matching differ from diffusion?
Flow-matching learns continuous flows from noise to data patches directly, often needing fewer iterative steps and enabling a single Transformer stack. Diffusion typically relies on separate denoising modules and heavier sampling pipelines.
Why were artifacts common in NextStep-1?
Numerical instability in high-dimensional continuous latent spaces during RL and AR flow prediction could induce blocky/grid artifacts and patch inconsistencies.
What exactly did RL improve in 1.1?
RL post-training focused on visual fidelity objectives, improving textures, reducing artifacts, and stabilizing patch transitions.
Is NextStep-1.1 documented?
Code and models are available on GitHub and Hugging Face; a formal technical report has not yet been released.
How does this compare to diffusion-based leaders?
While diffusion still leads many benchmarks, NextStep-1.1 shows that AR flow-matching can close the gap while staying architecturally simpler for unified multimodal pipelines.
Conclusion
NextStep-1.1 demonstrates meaningful progress in AR flow-matching: RL-enhanced fidelity and practical stability fixes without reverting to heavy diffusion. In a year when coding, agents, and multimodality define the battlefield—and IPOs reshape capital dynamics—Step’s update signals continued commitment to core modeling and deployable ecosystems. If you need to convert images to sketches or turn sketches back into realistic images, you can try Sketch To (https://www.sketchto.com/).
Transform Your Images with AI
Turn sketches into stunning images, remove backgrounds, swap faces, and more — all powered by AI.
Try Sketch To FreeShare
Sketch To
Tech writer covering AI tools, image processing, and creative workflows.
Related Articles

What Is Gemini Omni? Google's Multimodal Image AI
Gemini Omni is Google's multimodal AI image model. Learn how it works, where it shines, and when a sketch-to-image tool wins.

Recraft V4: Image Generation with Design Taste
Explore Recraft V4, the latest AI model for image generation that emphasizes design taste and artistic direction.

Qwen-Image-Layered: Layered Decomposition for Editability
Introducing Qwen-Image-Layered, a model that decomposes images into RGBA layers for precise, consistent, and inherently editable workflows.